 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilizing Priming to Identify Optimal Class Ordering to Alleviate Catastrophic Forgetting
Dec 24, 2022



In order for artificial neural networks to begin accurately mimicking biological ones, they must be able to adapt to new exigencies without forgetting what they have learned from previous training. Lifelong learning approaches to artificial neural networks attempt to strive towards this goal, yet have not progressed far enough to be realistically deployed for natural language processing tasks. The proverbial roadblock of catastrophic forgetting still gate-keeps researchers from an adequate lifelong learning model. While efforts are being made to quell catastrophic forgetting, there is a lack of research that looks into the importance of class ordering when training on new classes for incremental learning. This is surprising as the ordering of "classes" that humans learn is heavily monitored and incredibly important. While heuristics to develop an ideal class order have been researched, this paper examines class ordering as it relates to priming as a scheme for incremental class learning. By examining the connections between various methods of priming found in humans and how those are mimicked yet remain unexplained in life-long machine learning, this paper provides a better understanding of the similarities between our biological systems and the synthetic systems while simultaneously improving current practices to combat catastrophic forgetting. Through the merging of psychological priming practices with class ordering, this paper is able to identify a generalizable method for class ordering in NLP incremental learning tasks that consistently outperforms random class ordering.
Incremental Deep Neural Network Learning using Classification Confidence Thresholding
Jun 21, 2021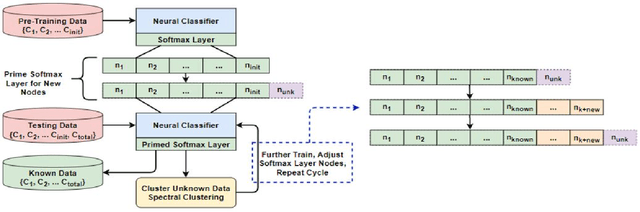
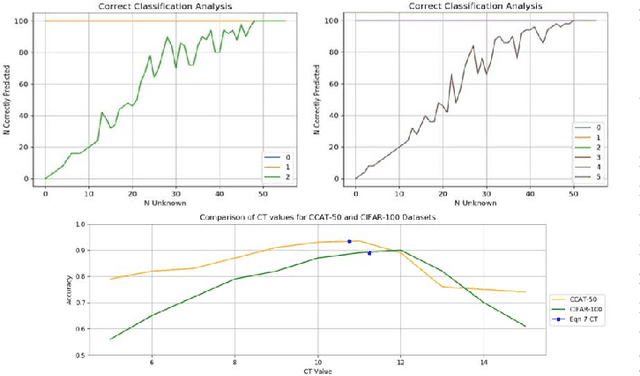
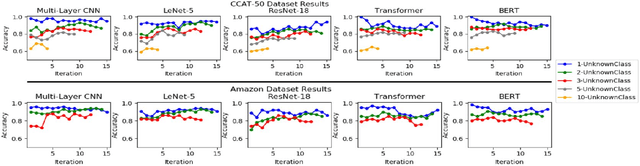
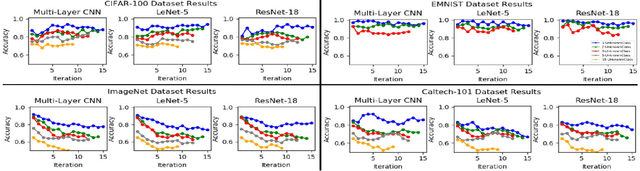
Most modern neural networks for classification fail to take into account the concept of the unknown. Trained neural networks are usually tested in an unrealistic scenario with only examples from a closed set of known classes. In an attempt to develop a more realistic model, the concept of working in an open set environment has been introduced. This in turn leads to the concept of incremental learning where a model with its own architecture and initial trained set of data can identify unknown classes during the testing phase and autonomously update itself if evidence of a new class is detected. Some problems that arise in incremental learning are inefficient use of resources to retrain the classifier repeatedly and the decrease of classification accuracy as multiple classes are added over time. This process of instantiating new classes is repeated as many times as necessary, accruing errors. To address these problems, this paper proposes the Classification Confidence Threshold approach to prime neural networks for incremental learning to keep accuracies high by limiting forgetting. A lean method is also used to reduce resources used in the retraining of the neural network. The proposed method is based on the idea that a network is able to incrementally learn a new class even when exposed to a limited number samples associated with the new class. This method can be applied to most existing neural networks with minimal changes to network architecture.
Moving Towards Open Set Incremental Learning: Readily Discovering New Authors
Oct 28, 2019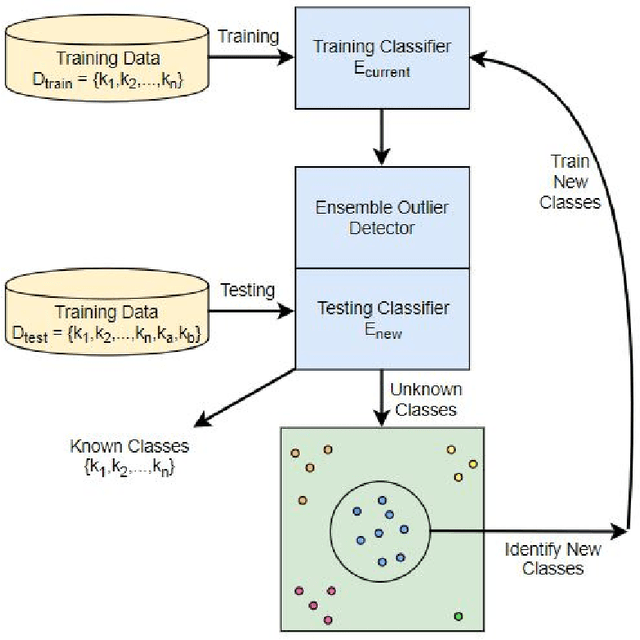
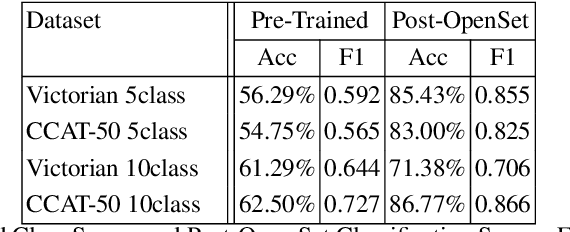
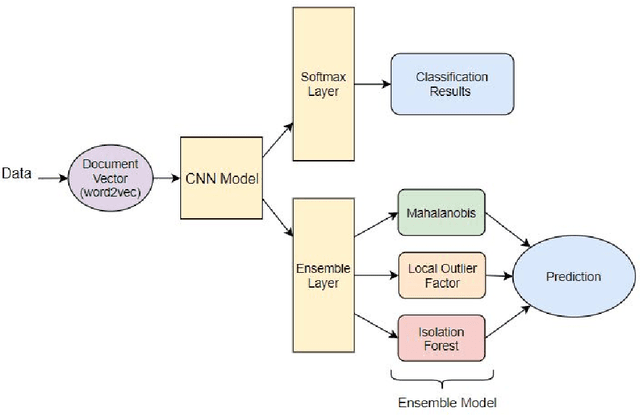
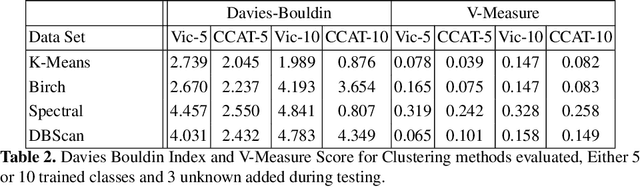
The classification of textual data often yields important information. Most classifiers work in a closed world setting where the classifier is trained on a known corpus, and then it is tested on unseen examples that belong to one of the classes seen during training. Despite the usefulness of this design, often there is a need to classify unseen examples that do not belong to any of the classes on which the classifier was trained. This paper describes the open set scenario where unseen examples from previously unseen classes are handled while testing. This further examines a process of enhanced open set classification with a deep neural network that discovers new classes by clustering the examples identified as belonging to unknown classes, followed by a process of retraining the classifier with newly recognized classes. Through this process the model moves to an incremental learning model where it continuously finds and learns from novel classes of data that have been identified automatically. This paper also develops a new metric that measures multiple attributes of clustering open set data. Multiple experiments across two author attribution data sets demonstrate the creation an incremental model that produces excellent results.